Is Data Lakehouse the answer to bringing order to your chaotic Data Lake or speeding up the slow progress of your Data Warehouse? If you’re about to introduce a cloud data platform, do you need to rethink your architecture?
There have been huge advances in how we build data platforms in recent years and new concepts and strategies are flooding in all the time. Not only are the big cloud providers Microsoft, AWS and Google embarking on major ventures, companies like Data Bricks are marketing their Delta Lake with great success right now, and Snowflake continues to be hot on the market.
I’ve been working as a developer and architect for almost 15 years in Business Intelligence and I thought I’d try to figure out what this is all about – is it a paradigm shift or just clever marketers doing what they do best? There have generally been two main strategies that have dominated the market in recent years, with Data Lakehouse aiming to be the perfect compromise for the two become one.
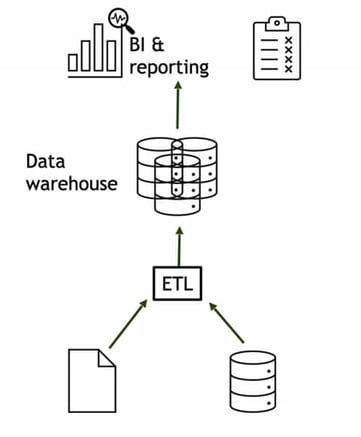
Data Warehouse
A Data Warehouse is largely for compiling data from different places in a way that makes it easy and fast to create analyses and reports and has been around for over 30 years in various forms. A database where we have common definitions and calculations of our most important key figures and how they relate to each other – Aspiring for “a Single version of the Truth” for an organisation where it is easy to consume high-quality information for many better decisions.
By definition, building a Data Warehouse is about trying to create order, so that more people can work more data-driven in an easier and faster way without having to worry too much about the quality of the data and whose numbers actually add up.
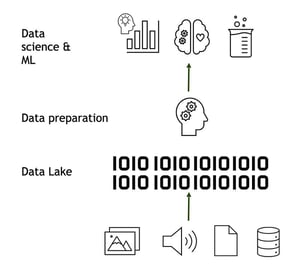
Data Lake
Just over 10 years ago, Big Data burst onto the scene with a bang and whole new ability to store and process files of different types in large volumes. Over time, we could see a parallel track forming with data platforms based on different variants of Hadoop solutions, which we have recently started to collect under the term Data Lakes. Often driven by exactly the ability to handle large, fast or complex data, others with a desire to focus more on the analytics ability rather than reporting.
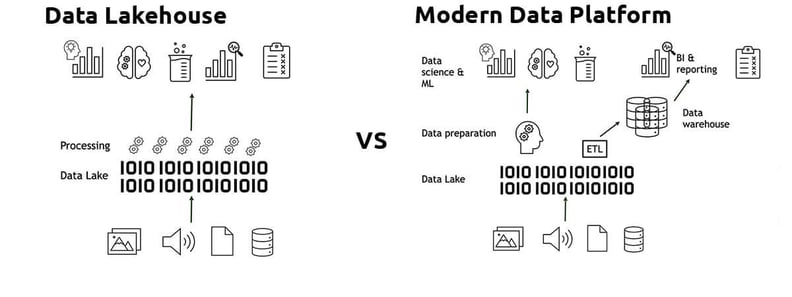
Three challenges in a modern data platform
However, in a modern cloud computing platform, things are often not as black and white as they are sometimes made out to be; we have long used the benefits of Data Lake along with the strengths of the database in the overall platform. Modern DevOps and the ability to scale performance has also dramatically reduced the initial cost of introducing a data warehouse. Those who have gone for a Data Lake strategy have often started to build multiple layers into their structure allowing them to better reuse calculations and get more structure in their data. So what main challenges does a Data Lakehouse actually address?
1. Schema on Read vs On Write
Defining a set of information with a schema is useful for creating clarity for users and increasing the degree of reusability and data quality. It becomes a clear interface where information is presented in a simpler way than just a pile of files as is often done in a Data Lake. Something that requires great knowledge to make a correct extract and this is something that Data Warehouses has always taken great care to get right.
However, one problem that arises when dealing with larger data sets in a Data Warehouse is that data needs to be moved through different layers in a database (schema-on-write), often in accordance with a standard ETL process. Something that often takes time, computer power and increases the risk that some part will not work. In addition, if you realise later that you want to reprocess the data in a different way, this can mean long and complicated reloads. Here there is great potential in separating the computational logic from the storage, as long as we can get good enough performance in the readout.
Data Lakehouse solves this problem through Schema-on-Read, i.e. not having to physically write the data to disk but rather as views of a set of files.
2. Dimensions
A simple thing like keeping your dimensions in good order, e.g. customers, products and departments is a challenge if you built a solution based on files in a Data Lake. In a Data Warehouse this is rarely a problem, either you update a customer row with the latest information or you have some kind of history management. This is not something that has a simple solution if customer information is scattered across a lot of files and you may have to read through thousands of files to find what the address of a customer was a year ago.
There is great potential here to speed up the process, especially for those working with freer analyses, and also to increase the quality of the analyses. In a Data Lakehouse this should work as smoothly as in a database, but it looks very different depending on the provider and implementation.
3. Business Intelligence + Data Science
A platform to support the needs of both Data Science and traditional BI enables us to leverage and put into production to a greater extent advanced analytics in reports, dashboards and operational processes. Often the real value of advanced analytics lies in when they come into wide use, where the many small decisions can be optimised. If teams can also work together more, the risk of duplicated work is reduced and we can get even more value out of the business.
Conclusion
I think we should constantly challenge the way we work to see if we can do it better and more efficiently. There is much to be gained by not getting stuck in the idea of needing a database to build a Data Warehouse, and we have seen countless examples of failed attempts to build financial reporting on top of a Data Lake, often ending up with a database being built on top of the Data Lake anyway. Data quality in a Data Lake without very tight and strict management always stagnates in quality over time.
As far as I can tell, a Data Lakehouse is nothing more than a natural evolution of a Data Warehouse but without using a database. We will certainly see development in this direction in the future, and the way to get there is probably some kind of hybrid variant. So think about the conditions and needs in your organisation, while the most important thing is to actually start building. With a good structure in your layers and good meta-data management, adjusting at a later stage is easy.
Hvis I som mange andre virksomheder bruger Microsoft Teams og også arbejder i fællesskab om at analysere eller forecaste med data, så er der godt nyt. Der er i Januar 2023, kommet en opdatering til Power BI integrationen i Teams og det gør det nu endnu nemmere at dele rapporter og indsigter med dine kollegaer.
Du kan dele Power BI-rapporter og dashboards i Teams-kanaler, så alle kan se og samarbejde om dataene. Du kan også bruge Teams-funktioner som kommentarer og @-mentions til at samarbejde og diskutere rapporter og data.
For at komme i gang skal du først oprette en Power BI-konto og derefter integrere den med Teams. Derefter kan du dele rapporter og dashboards med dine kolleger ved at indsætte dem i en Teams-kanal.
Når du har delt en rapport eller et dashboard, kan du og dine kolleger interagere med dataene ved at tilføje kommentarer, stille spørgsmål eller anvende @-mentions. Dette gør det nemmere at samarbejde om dataanalyse og beslutningstagning.
Så kort og godt, Power BI i Microsoft Teams gør det nemt for dig at samarbejde med dine kolleger om data og træffe datadrevne beslutninger.
Er i endnu ikke kommet i gang med at analysere data eller mangler hjælp til at komme i gang med et BI-projekt eller Power BI så kontakt Random Forest til en uforpligtende snak om hvordan vi kan hjælpe jer. I kan også læse mere på vores hjemmeside her.


