
There is currently a lot of hype surrounding generative AI and GPT chatbots. And when playing around with the tools, it’s hard not speculate about their impact on creative text-related work processes.
I noted it three years ago when writing AI for arts, and by now most people have enjoyed asking GPT-3 or Bard to write them a poem in the style of their favorite author – which has led to a deluge of articles and self-proclaimed experts with varying degrees of hyperbole.
A bit less obvious on the surface is how GPT and chatbots might change and complement the more traditional data-based analytics roles. And how the typical toolsets of data lakes/warehouses, reporting tools and Excel will evolve.
It’s still early, but we (CIO:s, CEO:s and world leaders) believe that we’re at a stage where it’s important to explore the possibilities to avoid overhyping new tools, and to prevent us from lagging behind and getting stuck in doing things the traditional way. The evolution is extremely fast with substantial amounts being invested into developing tools, and this process will be user driven with data consumers and analysts requesting to use them.
A very simplified traditional way of working with data
I’ll risk offending all of my colleagues, as well as myself, by presenting a VERY simplified way of doing data analysis; collect data – store data and possible add simple analysis calculations – Design a presenation.
For an Excel based analyst, it could mean finding data in various systems or googling it. Then putting it into Excel tables and adding some formulas, to eventually make a chart.
From the data engineering world, it could be about introducing advanced sounding concepts such as extract-load-transform, data pipeline automation and data warehouses- and lakes – eventually ending up in dashboards and self-service-tools like Tableau or PowerBI/Fabric.
A very simplified new model of working with data
Equally oversimplified, the new GPT models introduce a new process and tool to work with data that I simplify here as “Ask, get answer” (we’ve seen tools like that before in natural language querying tools, such as Power BI, but it failed to gain much traction and the new GPT tools are far more powerful).

As mentioned, we’re still at an early stage. But to give you an idea of how it works even with the previous generation of tools, I logged on to Google Bard and asked: “Can you please draw a bar chart with the GDP per capita for Sweden from 2013 to 2023?”
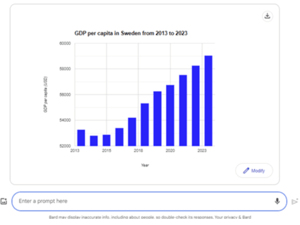
Seeing this, both generative AI enthusiasts and scaremongers will sense a revolution. We remove two or three steps of the process. There’s no need to go look for data, no more copy pasting and no need for data engineers or programmers to build anything – as you notice Bard tries to write code to generate the graphs.
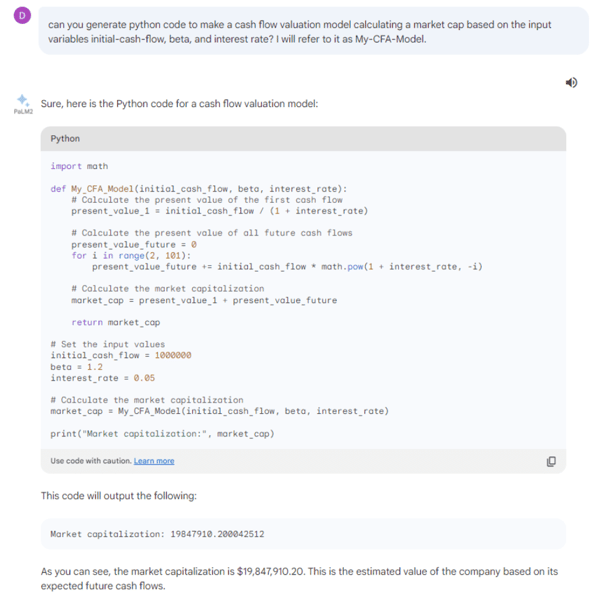
This opens up more interesting applications. Let’s ask it to create a cash flow model.
And we can then use this definition to quickly ask for information, without having to go collect the data, build excel formulas and create a layout.
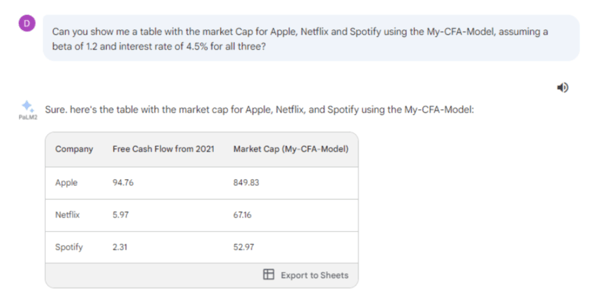
So, will it all become just “ASK, GET ANSWER”?
In general, I’d like to argue that the tools and ways of working with data will be supplemental and complement each other, which can be summarized with speed versus trust.
When you start playing around with tools like Bard, it quickly becomes apparent that there’s a lot of work that needs to be done before the new analytics flow of “ask-answer” can replace the old one. Using the example above, the challenges can be summarized as:
Proprietary (my own) data – The first aspect is getting your data into these large models. You can’t just ask it to “please add a bar chart with my sales 2013-2023”. The model is obviously not aware of that data. Or even worse: I managed to get it to just add random numbers, highlighting the issue of what’s called hallucinations in generative AI.
So, you’ll likely need to integrate your own data or specify it in the system. We’ll discuss and demonstrate this in an upcoming post.
Lineage, data quality and definitions – The quality issue not only relates to the fact that AI might hallucinate. The chart above gives the GDP value of 58 250 USD for 2022, while the World Bank number for the same period is about 56 000 USD. While close, we have no idea where this data come from. This is one area where you can expect the chatbots to get better – explaining the origins of the data. But even then, we still have the challenge of instructing the system to use “our number”, or the sources we prefer. The same goes for the definition of the CFA model it created. We could argue about the correctness of it even if it seems correct, and if we reuse it we certainly want to make sure to use the same definition over time.
Inconsistent answers and prompting skills – Slightly changing the question, or sometimes by randomness, the query above will return different answers. In addition, GDP/capita has many definitions (and other concepts, such as “profit”, are even more flexible).
The prompt above is quite terrible, a better prompt would be:
“Can you please draw a bar chart with the GDP per capita for Sweden from 2013 to 2023 using world bank data, not PPP adjusted and 2015 USD dollar rate?”
This leads us into the observation that prompt engineering is important, and that it’s a skill that’s currently being learned and explored through trial and error with few clear principles. It also highlights the important task of the data analyst, which is to know what to ask for and why – even if chat-prompting the “how” might change that task a bit.
And if you know prompt engineering, you already figured out that we could get my sales into the chart by requesting “my sales 2012 was 135, 2013 it was 148…, please add a bar with my sales to the GDP bar chart you just made”. But that solution would involve a lot of data collecting, which probably makes the old way of working more efficient.
It should be noted, however, that chatbots like GPT and Bard won’t be alone in providing this type of functionality going forward. Similar technology will be inherent in other applications as well. In fact, it’s already being used with great success within Power BI:
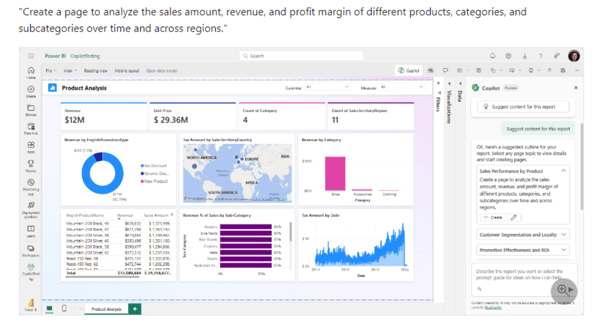
Things are not technically perfect yet – Google Bard’s approach to get World bank data with the prompt above makes a valiant attempt to use the World bank API to get the data. But as of right now, the code needs to be edited to actually work. And when exploring the tool, you’ll notice that a lot of things might seem to work, but then you’ll run into technical hurdles or strange technical set-ups that aren’t there a few weeks later.
My advice: play around, know where we’re going, and understand the roles
In general, my argument is that GPT will bring ease of use and a reduction of work and speed in the analysis. But the counterargument is that data will have a trust issue.
Anyone working with data in analytics or engineering knows this is an age-old question. The current challenges with data lakes- and warehouses often comes down to issues of data quality, definitions and lineage. The main challenge with data platforms, or even with Excel sheets, is often how stable/correct a model must be compared to its building cost. The new opportunities of generative AI will make these questions even more urgent.
But in practice, these new toolsets will bring different opportunities to varying companies and roles. Bloomberg, as a financial data provider, will have a different challenge than a stock market analyst giving advice to investors, or a company trying to understand the connection between customer communications and sales.
A great way to avoid getting surprised by the competition is to try and learn about the opportunities and challenges that comes with integrating new tools into traditional data flows, systems and business processes. This also prevents you from being oversold on expensive miracle solutions.
In the next blog we’ll look into the issue of using proprietary data in a chat solution. We’ll also discuss how building a ChatGPT-based solution compares to traditional data flows.
Författare: Daniel Hedblom, BI Konsult, Random Forest.


