
Employee Churn Prediction in 5 steps. Make use of machine learning to prevent your employees from leaving your organization.
Look for the signs
Given that employees are one of the most valuable assets of any organization, losing an employee has a negative (detrimental) impact on several aspects of business activities. Loss of competence, worsened productivity and increased hiring costs are just a small fraction of the consequences associated with high employee churn. Making your best employees stay is in all aspects much better than having to hire new people to replace the ones that leaves.
At the same time, it is often not known why employees leave and how to prevent it. There are often many theories, but few based on actual facts. The decision to quit can stem from different sources and the reason to quit differs depending on the organization in question.
As a part of her master thesis at Random Forest, Anna Gentek has built an emplyee churn model for a customer in the healthcare industry and made some remarkable findings.

Crunch your data to learn about employee churn and retention
How to build your own model in 5 steps
[There are several types of machine learning techniques that could be used to build an employee churn prediction model, including supervised, unsupervised, and reinforcement learning. This article focuses on supervised machine learning methods.]
Traditional churn prediction model consists of five main components. These are the following:
1. Data Acquisition
The first step in any classification problem is to collect relevant data. Since the goal is to model the behavior of former and current employees, the collected data should contain as many attributes, also called features, that describe an employee as possible. The dataset depends on the type of information that is available in company’s HR system, and therefore, it might differ for two different organizations and two churn prediction models.
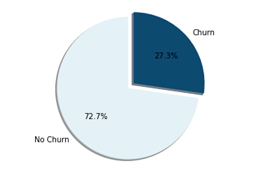
30 features were extracted for the healthcare organization, including attributes such as occupation rate, salary, time at the company, job role or distance to work, to name a few.

2. Data Preprocessing
The quality and the size of the acquired data set is essential when building an accurate churn prediction model. Insufficient or poor-quality data often results in a model that is not able to properly learn and detect hidden patterns and correlations in the data, leading to wrong predictions and lower accuracy. To assure the quality and desired format of the data, the second step is to apply required preprocessing techniques, including data anonymization, data cleansing, data encoding, scaling, and data transformation.
3. Feature Selection
Higher number of attributes increases the dimensionality and complexity of the studied problem.
Therefore, the feature selection becomes crucial part when building churn prediction model. Removing the irrelevant, redundant, and noisy features reduces the dimensionality and complexity of the data set, leading to an increased learning performance, improved training time, and higher model interpretability. Depending on the nature of the studied problem, several feature selection methods, including filter, wrapper, embedded and hybrid methods could be used to identify and extract the most important features only.
 |
 |
4. Model Selection and Training
Now that the acquired dataset is assembled and preprocessed, it is time to train the model. But which model should you choose?
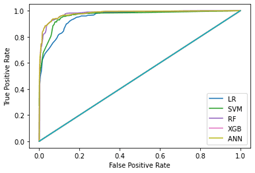
Different models perform differently depending on the environment. The model you choose, should be adapted to the investigated organization and the size of dataset and the extracted features. Additionally, when trying to understand why employees leave, the models that provide more interpretability are of preference too. Therefore, a common approach is to apply several models and compare in order to find the optimal choice.
5. Evaluation
How do we evaluate the performance of the applied models? The applied models can be evaluated using several performance measures, depending on the studied problem. From the business perspective, recall, focusing on churning employees is said to be one significant measure for employee churn prediction model.
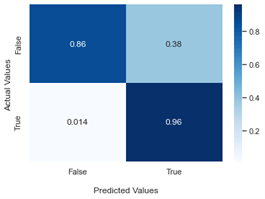
The findings?
Using these five steps, we were able to build an employee churn prediction model that could successfully classify 95 out of 100 churning employees with Support Vector Machine being identified as the optimal prediction model.
Being able to predict and act upon employees in danger of leaving would be really great in most organizations. Having looked at a big number of factors extracted from available systems, including salaries, sick days, distance to work, education etc. you can although not all factors are represented in systems make good predictions and have the chance to be more proactive and increase your employee retention.
Additionally, my findings show that among all the investigated variables, the variables related to employee benefits were mostly correlated with the high rate of churn. So being generous and helping your employees to use company benefits to a high degree is in this case indeed profitable.
Author: Anna Gentek
Data Scientist amd Business Intelligence Consultant at Random Forest



